Git Basic Principles & Concepts (for new developers)
One of the core tools used in many software development circles is Git - a 'version control system' which enables individuals and groups to have a complete record of all the code changes throguhout the life-cycle of a project. As you can imagine, starting to use version control to save progess, rather than just the usual ctrl + S takes a bit of getting used to!
As a new developer, learning all of this stuff is pretty intimidating along with all of the other new knowledge. So I wrote the following guide, which is the document I would've like to have been given when I started.
Introduction
Have no fear, Git is here to help. Nothing is lost, once commited to a repository. And there are many ways to organise your work, although this flexibility does mean it can be more complicated to store/locate your work. Commits are the core concept though, so get used to them.
It is useful to append the idea of 'always commit your work' to the paradigm 'always save your work'.
Git stores different "versions of reality" and you can switch between them like a multiverse! If you want to branch off and do something weird and crazy this is perfectly fine - everything in the other universes (branches) is unharmed.
Here are a couple of good tutorial links to get you started:
- Practice and visualise manipulating an example Git repository
- Hands on, step-by-step, bite-sized explanation of the core git concepts
Commits
A commit is a change to a set of files. It can consist of new files, altered files, deleted files and directories etc. In the real world a commit represents a logical/intuitive point to package some work you've done. After a certain piece of functionality has been completed, or everything required for a ticket has been done, or just at the end of the day (althought this isn't considered good practice by all as it results in incomplete work in the repository). Every commit is given it's own message, so you have the opportunity to show why this is a logical or intuitive place to be committing.
There can be a very large number of commits in a repository, which are connected in a variety of ways. One thing that is important to get your head around is that you can shift the whole filesystem to be the way it was at any commit. This is referred to as a "checkout" of a certain place in the structure (although the command is used slightly differently elsewhere). The process of checking out moves the "HEAD" to a different place in the repository and therefore looks at a version of the files from a different point in history.
Staging Areas
The mechanism for creating commits is by placing the required changes, piece by piece if required, into the staging area. Git is aware of things that are in the 'work tree' (the filesystem you are looking at), that are different to the repository. It allows you to chose from these things by executing a command like these:
Put one file into the staging area:
~$ git add path/to/altered.file
Stage any changes within this directory:
~$ git add path/to/directory
This stages AND performs the next step - committing - all in one:
~$ git commit -am "useful message"
This is quicker but less flexible. Be sure to know which files are going into the commit. Also, this only adds files that are already in the repo. If you need to add a new file for the first time, you have to use 'git add' first.
After adding some files, you can do 'git status' to display everything staged for a commit in green. If you are happy with what is prepared (you can use 'git diff' to see the details of what has changed) you can go ahead and run:
~$ git commit -m "useful message"
That commit is now locked down in the repository. You will always be able to go back to it, event after future commits.
Branches
Branching in Git is the action of deviating a sequence of commits from any pre-existing sequence. This is like taking your code to another dimension - where it can't mess up anything in another one. The ability to branch gives lots of flexibility for different workflows and gives Git its characteristic look in diagrams.
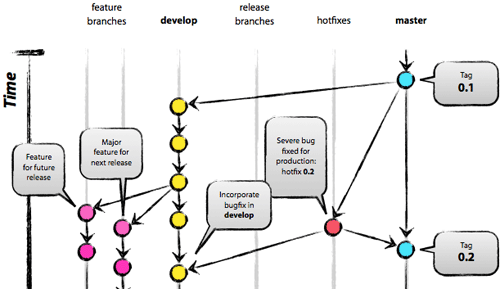{kind=link}
A typical workflow may consist of using a branch for working on a particular ticket or developing a piece of functionality. This "feature branch" will most likely deviate from a main development branch. Once created this branch will contain any number of commits working towards a finalised unit of work. After the work is ready, this branch can be merged back into the dev branch and this becomes the new start point for future feature branches.
Branchy Commands
Create a branch (relative to the current branch):
~$ git branch name-of-branch
This Branch will deviate from wherever HEAD is in the repo. Though the new branch will not be checked out at this stage.
List all available branches:
~$ git branch
Lists available branches.
Creates a new branch and checks it out in a oner:
~$ git checkout -b name-of-branch
Repositories
Most workflows will consist of interactions with different repositories. Typically you will use a hosted central repository (BitBucket, GitHub etc.) which multiple collaborators can send their work to. It is in the central repository that the main workflow (feature branching and managing merges) occurs.
It is good practice to keep your local repo as similar in structure to the central remote one, although this does not necessarily need to happen. In principle you can perform the command below between any arbitrary repos, and Git will do its best to handle any differences it encounters. For example, two repos may not have the same branch structure, i.e. branches with the same content may have different parent commits. This is not necessarily a problem, depending on the nature of the code changes, but it may explain issue with merges later on down the line.
Commands and concepts for moving changes between repositories.
fetch - Gets commits from a remote repository so they exists on a branch parallel to the local counterparts. So for example 'git fetch dev' gets a local version of the branch that is called "dev" in the remote repo (which is usually referred to as "origin"), but locally is called "origin/dev". This sounds confusing, but the idea of the "parallel" branches on fetching is illustrated in this interactive tool - just type "git fetch" in the command box!
pull - Does the above except it would also attempt to bring the local version of the "dev" branch up to date with any new stuff by performing a merge. The merge happens locally. The 'git pull' command acts on the current branch and is quite automatic. Here's a good summary of the differences between fetch and pull.
push - Attempts to send changes from local to remote. You may need to pull first to have the necessary information about the structure of the remote repo. Push requires Git to know what branch it's pushing to. You can specify that each time by executing 'git push origin branch-name', or you can set an "upstream branch" using 'git push -u origin branch-name' which lets Git know that it should always push between this pair of branches. Thereafter you can just do 'git push' and it knows where to go.
Stashing
Sometimes you are asked to "stash" when switching branches. Stashing takes uncommited changes and puts them somewhere safe for you to re-apply later.
If you are asked to do this, simply do a 'git stash' - to put the changes in the stash. Then go to the new branch with 'git checkout new-branch-name'. Finally 'git stash apply' puts those uncommited files onto the new branch.
The stash never goes away. You can always access older stashed items even if new ones have been created.
Why does this happen? For unstaged changes to files, Git thinks about the last commit that involved a change to that file - a "parent commit" (this may be the initial commit). If you do a switch that makes it unclear which parent commit to use for a file, a stash becomes necessary.
Merging (and conflicts)
Merging happens in various guises at various points in the workflow. Generally speaking, it involves making two branches into one so that the information in both is maximally represented. Most of the time the information can be matched up well, but sometimes it will be ambiguous as to which branch's change should be used. I.e. in some files there may be a different change to the same line(s) of code. When this happens Git will present the two options to you by writing them both into the file, using a certain convention to show which branch each is from. This is called a merge conflict. Fixing consists of simply editing the files and deleting the bits you don't need.
The basic command for merging is:
~$ git merge target-branch-name
This will bring any differences from the target branch into HEAD (current branch). If this is successful (usually) a new commit will be created which has two parent commits, although you can also create a fast-forward merge in some cases.
Hopefully these notes and basic principles will help you get to grips with Git!